Apache Spark:分布式并行计算框架(二)
1、Spark 有哪些优化
第一、公共优化
1、序列化(
Serialization)
Spark中默认序列化方式:
Java 序列化(Java serialization)
要求数据类型必须实现序列化接口Serializable,比如HBase数据库读取数据时,封装到Result
设置序列化为:Kryo 序列化
比Java序列化性能提升10倍以上
设置:
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")2、数据缓存(
Cache)
可以将RDD数据缓存,设置缓存级别StorageLevel
要么内存、要么磁盘、要么内存和磁盘(是否序列化)、要么系统内存(可以不管)
DataFrame和DataSet同样可以缓存,底层就是RDD
什么条件下缓存数据集呢???
可以提升数据计算效率
1. 数据集RDD被使用多次,考虑缓存,依据数据集大小合理设置缓存级别
2. 数据集来之不易,并且使用不止一次3、分区数目调整(
partition)
RDD分布式数据集,不可变的、分区的和并行计算集合,抽象的
无论批处理还是流计算(微批处理)计算结果,往往数据量很小的,当保存到外部存储系统时,最好降低分区数目
比如某日物流快递公司订单数据1000W,按照省份统计34条
resultRDD.coalease(1).forchePartition
将数据集保存外部系统时,最好针对每个分区数据操作第二、批处理优化
基本上使用SparkSQL离线数据分析,考虑SparkSQL中哪些优化即可。
1、spark.sql.shuffle.partitions
Shuffle时分区数目,默认值为200,实际项目中可能太大,有可能太小
Spark 1.x和Spark 2.x需要调整
Spark 3.x开始无需调整,新特性:自适应调整
只能开启功能以后,SparkSQL程序在运行计算时,依据Shuffle数据量自动设置分区数目
2、广播变量大小调整
SparkSQL在执行2个表的数据Join时,自动判断是否为大表JOIN小表,如果有1个小表的话,采用广播变量的方式广播数据,进行关联分析处理,避免产生Shuffle,提升性能。
参数:spark.sql.autoBroadcastJoinThreshold = 10M
比如小表数据大小为12M,完全可以采用广播JOIN方式,此时调整 广播表里大小阈值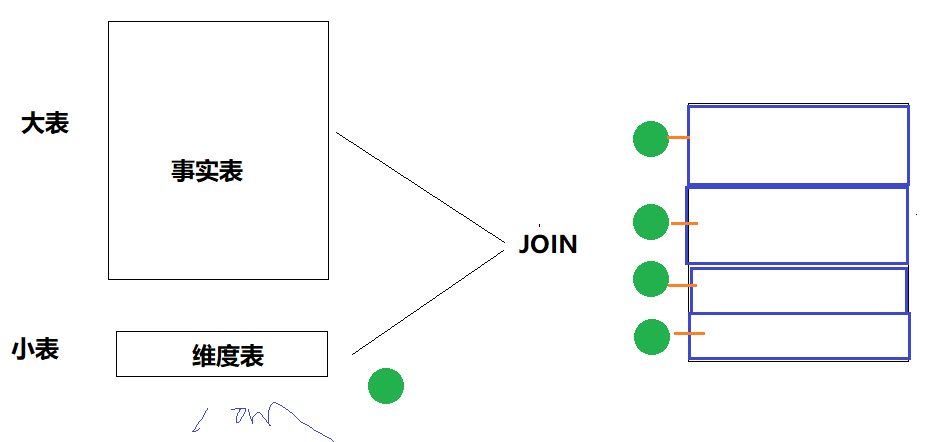
第三、流计算优化
要么使用SparkStreaming,要么使用StructuredStreaming分析数据,底层批处理(微批处理)。
1、限制高峰数据量
限制每批次处理数据量,给定一个阈值,通过压力测试确定的值
1)、SparkStreaming参数:
spark.streaming.kafka.maxRatePerPartition
2)、StructuredStreaming参数:
maxOffsetsPreTrigger,每次触发时,消费最大偏移量
针对SparkStreaming来说,为了更好处理流式数据,避免数据量太多,导致应用性能下降:反压机制
原理,依据当前处理数据量和处理时间,决定下一批次处理数据量2、数据本地性等待时间
https://spark.apache.org/docs/2.4.5/tuning.html#data-locality https://www.cnblogs.com/cc11001100/p/10301716.html
1、PROCESS_LOCAL:进程本地性,Task任务和Data数据在同一个JVM进程中
顾名思义,要处理的数据就在同一个本地进程中,即数据和Task在同一个Executor JVM中,这种情况就是RDD的数据在之前就已经被缓存过了,因为BlockManager是以Executor为单位的,所以只要Task所需要的Block在所属的Executor的BlockManager上已经被缓存,这个数据本地性就是PROCESS_LOCAL,这种是最好的locality,这种情况下数据不需要在网络中传输。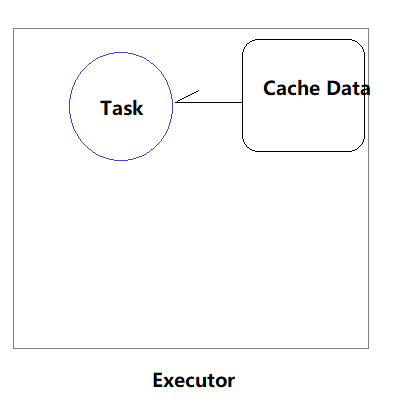
2、NODE_LOCAL:
数据在同一台节点上,但是并不不在同一个jvm中,比如数据在同一台节点上的另外一个Executor上,速度要比PROCESS_LOCAL略慢。还有一种情况是读取HDFS的块就在当前节点上,数据本地性也是NODE_LOCAL。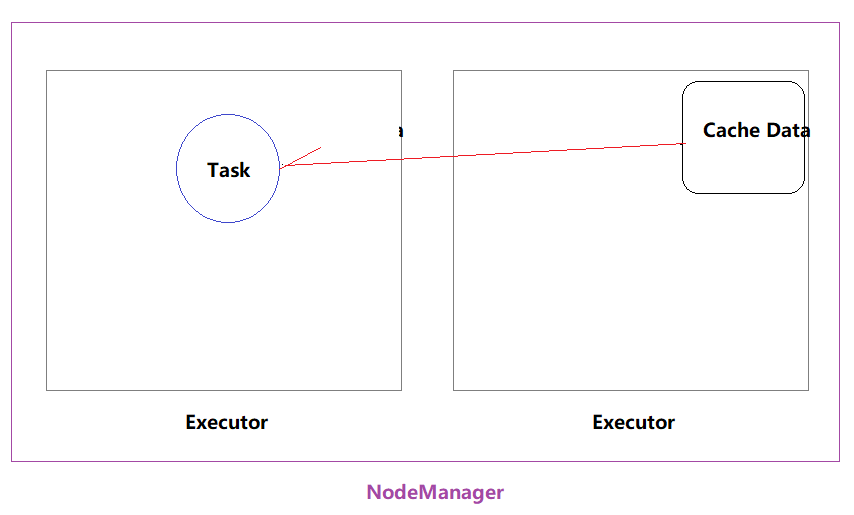
3、NO_PREF:
数据从哪里访问都一样,表示数据本地性无意义,其实指的是从MySQL、MongoDB之类的数据源读取数据。
4、RACK_LOCAL:机架本地性
数据在同一机架上的其它节点,需要经过网络传输,速度要比NODE_LOCAL慢。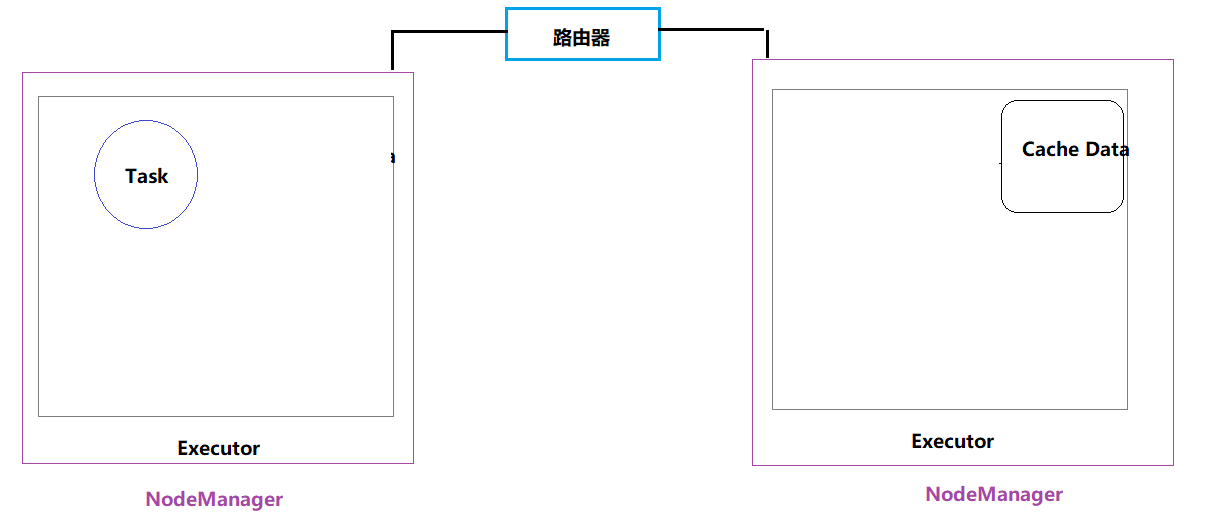
5、ANY:
数据在其它更远的网络上,甚至都不在同一个机架上,比RACK_LOCAL更慢,一般情况下不会出现这种级别,万一出现了可能是有什么异常需要排查下原因。 在流式数据处理计算中,设置数据本地性等待时间越小越好,不需要等待,直接使用某个数据即可,哪怕时最差:ANY都可以。
参数:spark.locality.wait,默认为值3s
可以设置为
spark.locality.wait=10ms2、SparkSQL 底层JOIN实现方式
SparkSQL底层处理2个表JOIN时方式:3种,自动选择合理方式处理数据
参考:https://www.cnblogs.com/JP6907/p/10721436.html
对于Spark来说有3中Join的实现,每种Join对应着不同的应用场景:
- 1、Broadcast Hash Join : 适合一张较小的表和一张大表进行join
- 2、Shuffle Hash Join : 适合一张小表和一张大表进行join,或者是两张小表之间的join
- 3、Sort Merge Join : 适合两张较大的表之间进行join
前两者都基于的是Hash Join,只不过在hash join之前需要先shuffle还是先broadcast。
第一、Broadcast Hash Join
大表和小表进行JOIN
将小表数据采用广播变量的方式,把数据广播到大表的每个分区中,进行JOIN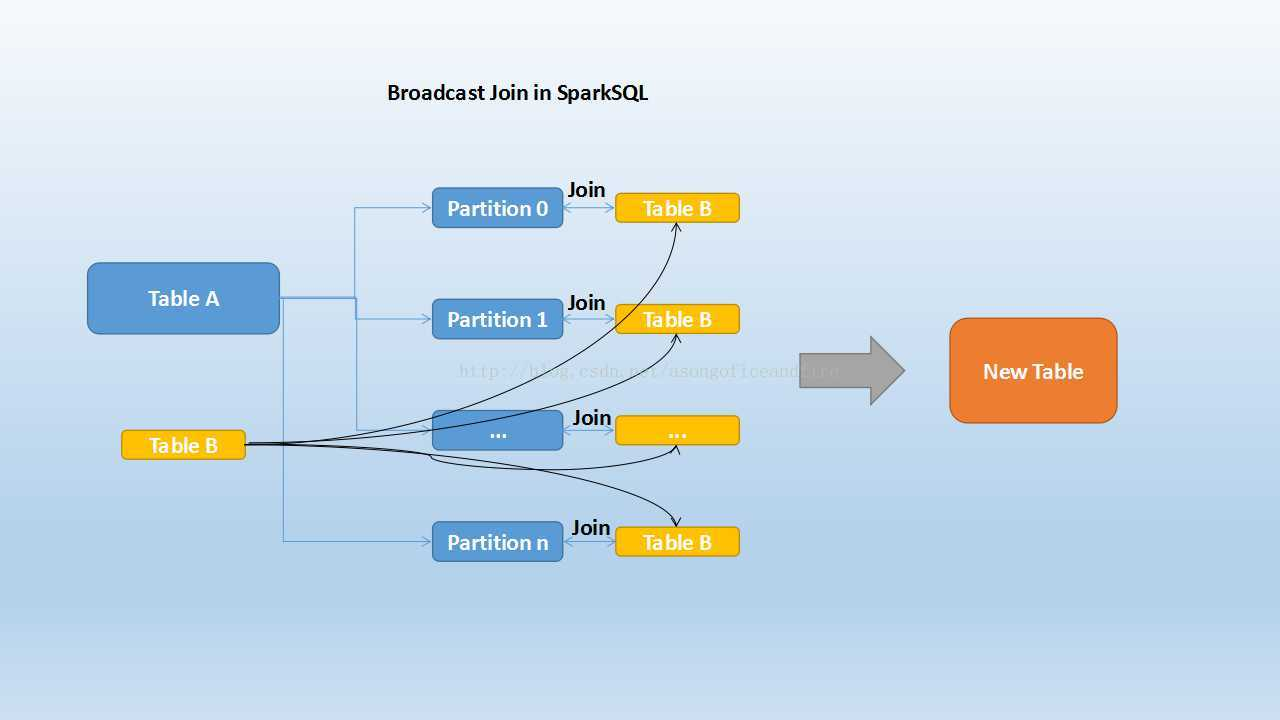
Broadcast Join的条件有以下几个:
1、被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M (或者加了broadcast join的hint)
2、基表不能被广播,比如left outer join时,只能广播右表第二、Shuffle Hash Join
大表与小表(数据量也挺大,相对大表来说,小一点)
对2个表的数据按照相同的字段进行重分区,并且分区数目相同
Shuffle :对2个表的数据进行重分区,字段相同,分区数目相同
tableA表1个分区 仅仅 tableB表1个分区 数据进行JOIN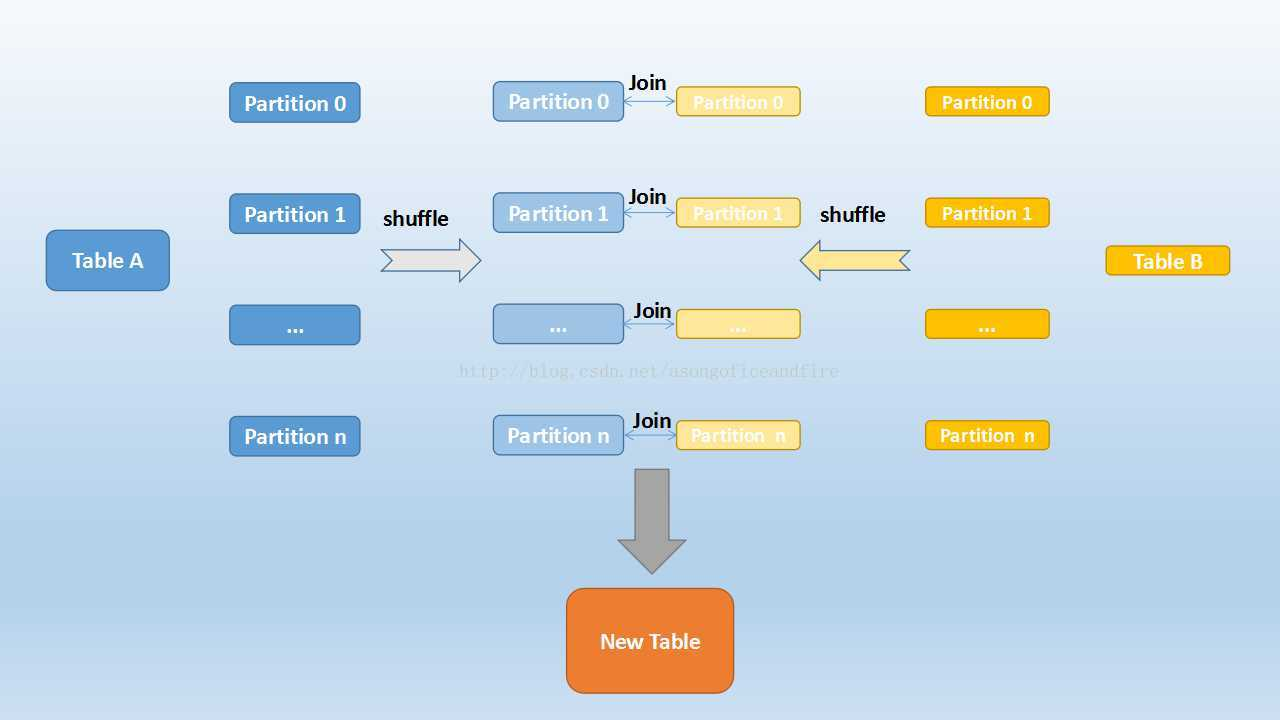
第三、Sort Merge Join
大表对大表
类似Hive中SMB JOIN,表的数据分区相同、分桶数目相同,并且桶数据排序的
首先,2张表进行重分区,分区字段key相同,分区数目相同
然后,对每个分区中数据进行排序
最后,表对表的 分区数据进行JOIN,此时关联时,不会扫描整个分区中数据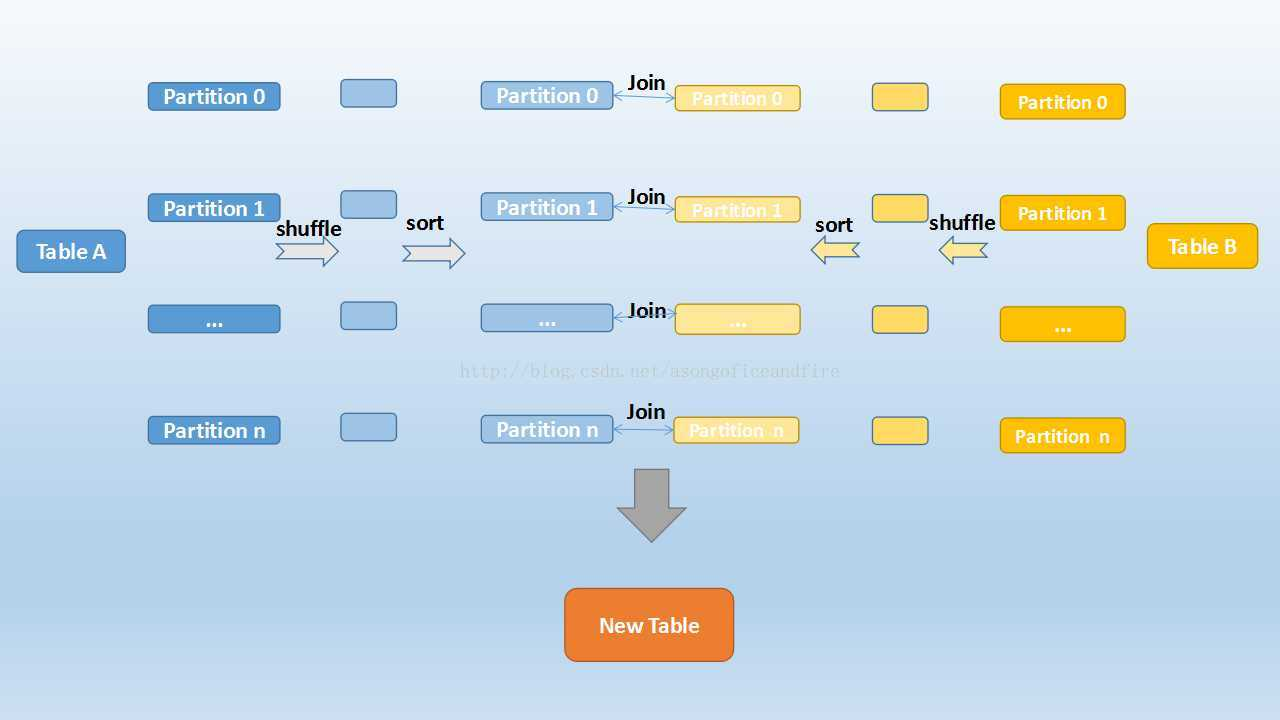
Apache Spark:分布式并行计算框架(二)
https://jface001.github.io/2020/09/28/Spark-Review-Day02/