Vol.12 Kafka 核心工作原理小记
消息队列简介
概述
消息队列MQ用于实现两个系统或模块之间传递消息数据时, 实现数据缓存
功能
基于队列方式, 实现传递消息的数据缓存
应用场景
- 实时高性能高吞吐量高可靠的消息传递架构
- 大数据应用: 作为唯一的实时数据存储平台
- 实时数据采集: 生产写入Kafka
- 数据数据处理: 消费读取Kafka
优点
- 解耦
- 异步保证最终一致性, 提高传输性能
- 限流削峰
缺点
- 运行更复杂, 必须保证消费队列是可靠的
- 数据安全保障更复杂, 必须保证生产和消费都是安全的
同步和异步
同步
- 概念
- 提交和处理是同步操作,立即就能看到结果,立即一致性
- 优缺点
- 安全但性能较低
异步
- 概念
- 提交和处理是异步操作,最终得到一个处理的结果,最终一致性
- 优缺点
- 性能更高但结果可能有误差
点对点模式
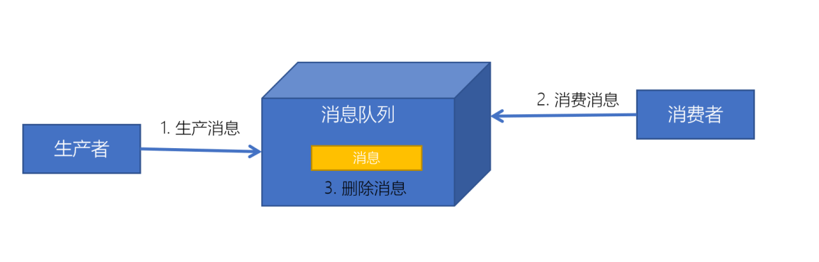
特点
- 数据只能被一个消费者使用
- 消费成功以后数据就会被删除,无法实现消费数据的共享
订阅发布模式
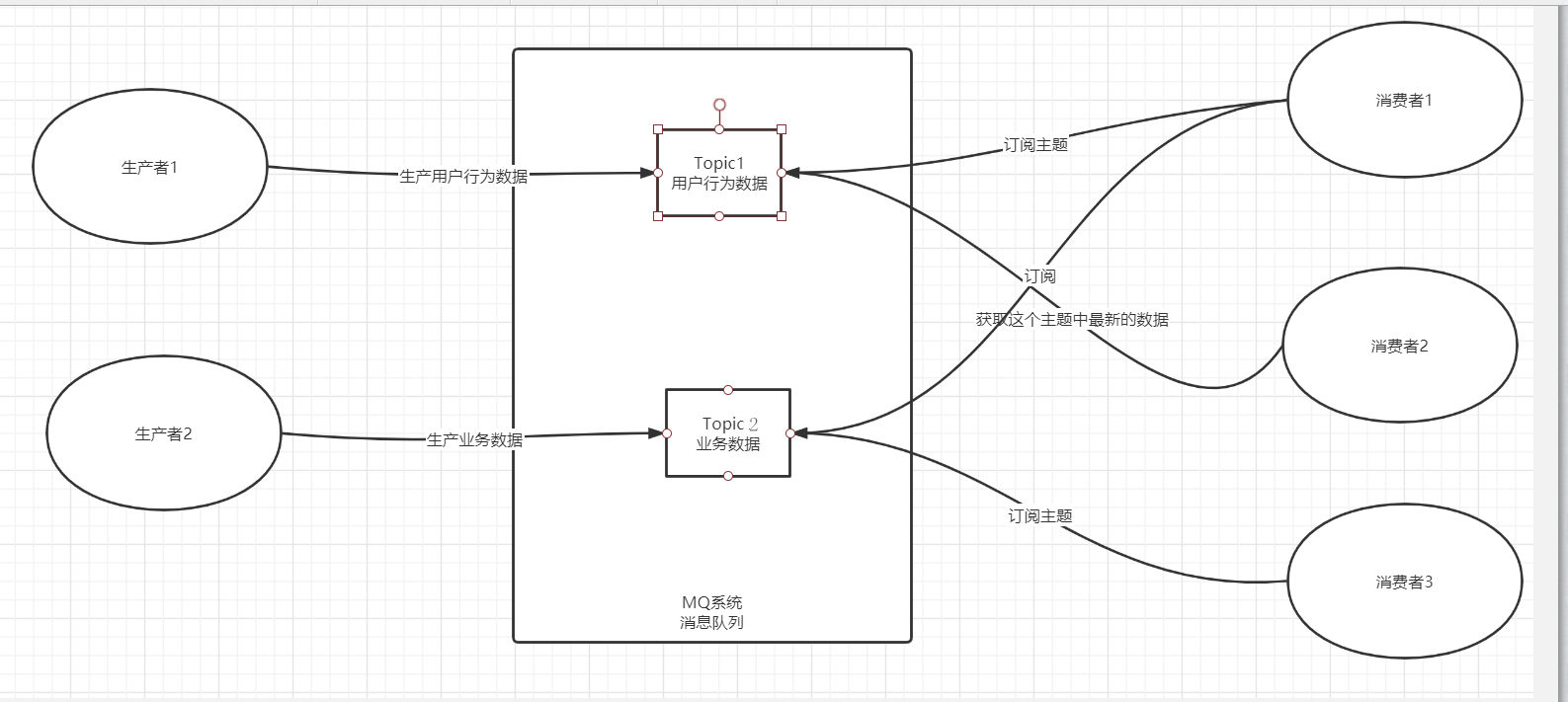
- 特点
1.一个Topic可以被多个消费者订阅
2.一个消费者可以订阅多个Topic
3.Topic中的数据可以实现不同消费者共享
Kafka基本介绍
概念
- 分布式的基于订阅发布模式
- 高性能高吞吐量高可用高灵活性高安全性的实时消息队列系统
功能
分布式流式数据实时存储
- 分布式存储
- 实时消息队列存储,工作常用
分布式流式计算
- 分布式计算KaflaStream
- 基本不用
特点
对比其它特点
- 适用于大数据量的临时性存储(安全+数据量较大)
- 缓存时间相对较长
高性能
- 基于分布式内存+分布式磁盘存储系统
- 顺序写入和顺序读取,索引
高并发
- 分布式并行读写
高吞吐量
- 分布式磁盘存储,没有使用HDFS
高可靠
- 分布式主从架构
- 节点备份机制
高安全性
- 数据安全保障机制
- 内存是操作系统级别
- 副本机制
高灵活性
- 根据需求添加生产者和消费者
应用场景
实时场景图示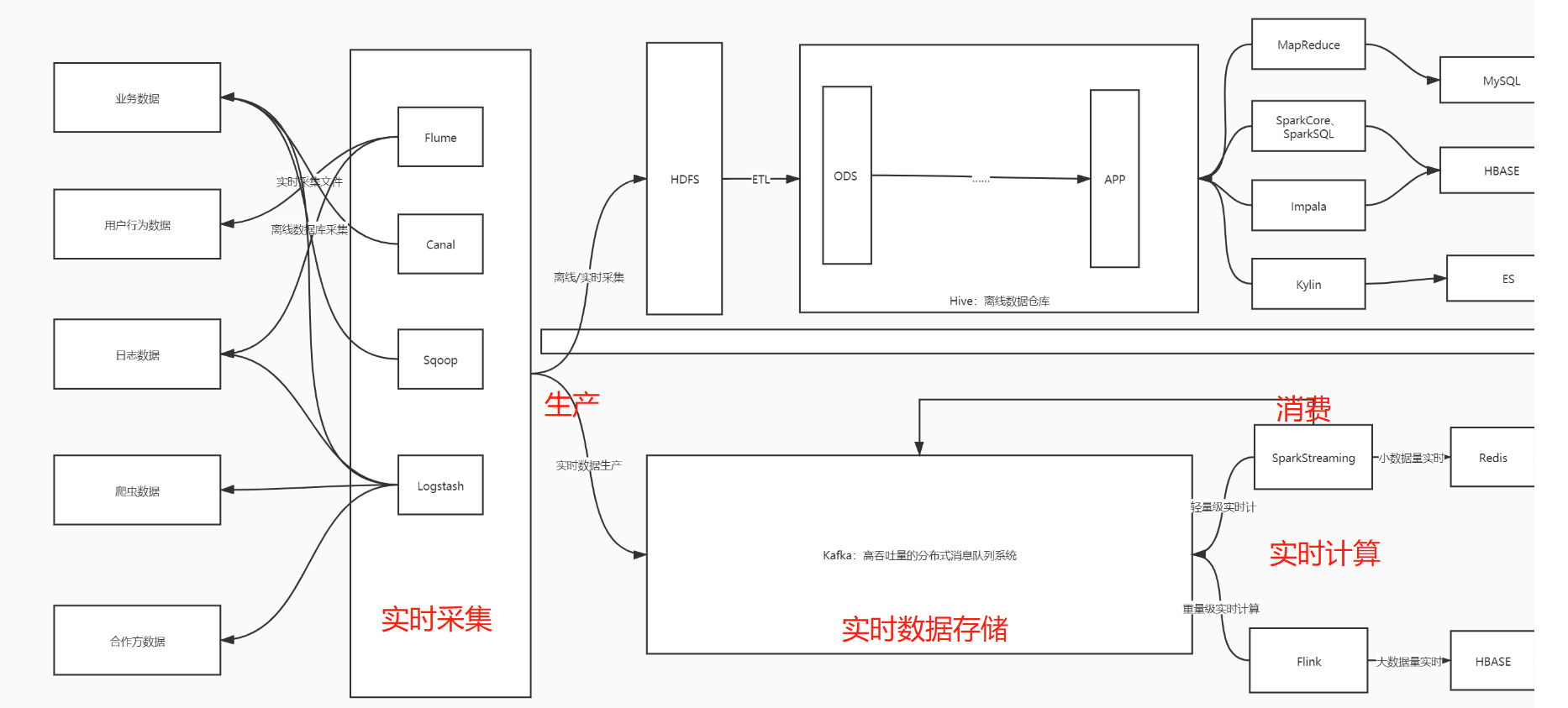
实时大数据,必用Kafka
- 离线数仓Hive
- 实时数仓Kafka
- Kafka生产者数据采集工具: Flume Logstash
- Kafka消费者实时计算程序: SparkStreaming Flink
结构概念
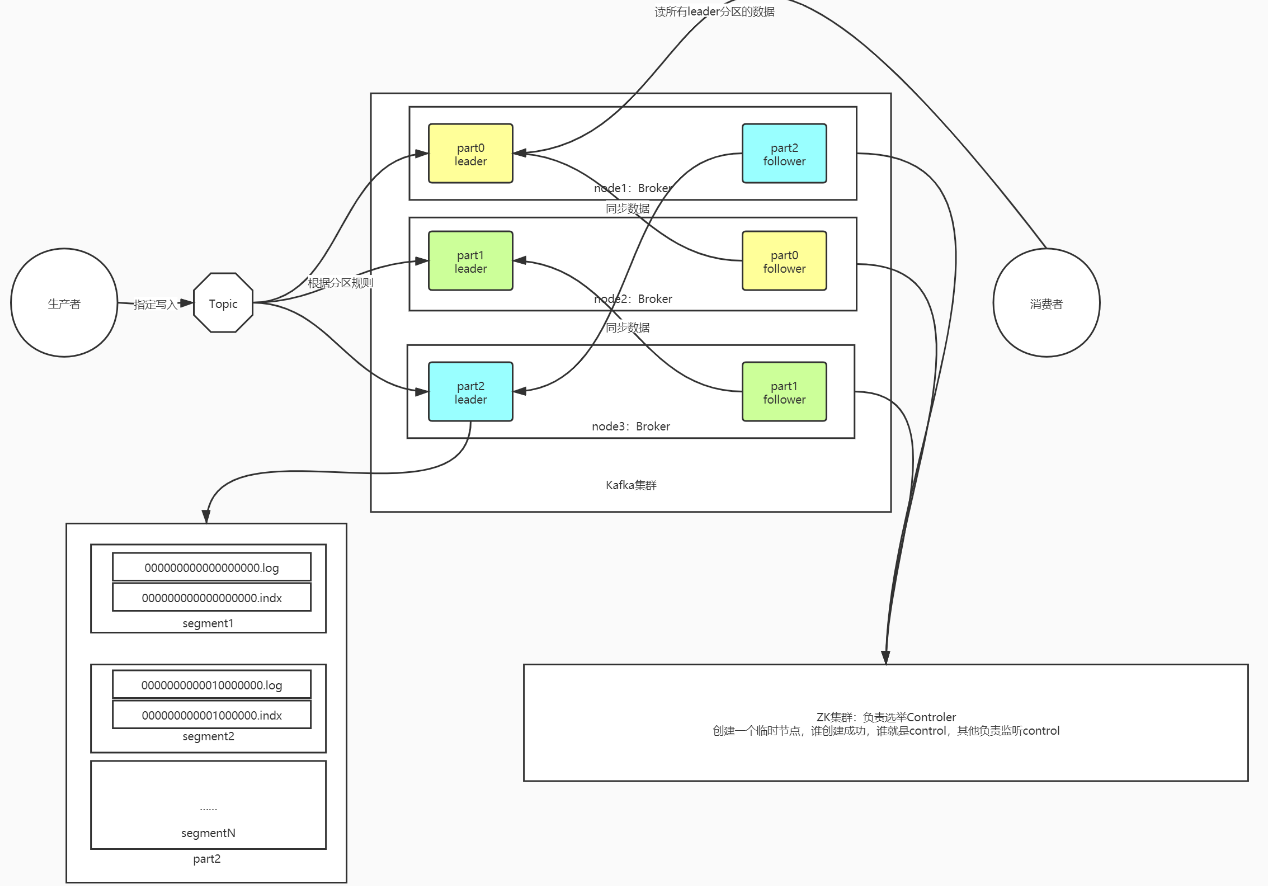
Producer生产者
- 负责将数据写入Kafka
- 生产环境一般是数据采集工具
Broker节点
Consumer消费者
- 负责从Kafka中消费数据
- 主要消费的数据是value
Consumer Group消费者组
- 必须以消费者组的形式从Kafka中消费数据
- 任何一个消费者必须属于某一个消费者组
- 消费者组中的多个消费者消费的数据是不一样的,合起来是完整数据
Topic数据主题
- 区分不同数据, 对数据进行分类
- 一个Topic可以划分多个Partition分区
Partition数据分区
- 用于实现Topic数据的分布式存储
- 一个Topic可以划分多个Partition分区
- 不同分区存储在不同的Broker上
- 根据一定的规则决定写入哪个分区
Segment分区内数据文件
概念
- 分区数据更细的划分
作用
- 可以加快数据检索效率
- 实现数据的删除处理
创建流程
- 每个Segment对应2个Segment文件
- XXXX.log真正存储的数据
- XXXX.index索引文件
- 数据写入Segment达到阈值会创建新的Segment文件
Offset每条数据在自己分区的偏移量
产生
- 数据写入Topic分区时,分区内部自动给每条数据进行Offset编号
级别
- Offset是分区级别,每个分区独立管理,从0开始
功能
- 消费者读取按照Offset来读取数据
- 保证消费者每次按照Offset顺序消费保证消息不重复不丢失
副本机制
概述
- Kafka通过副本机制来保证数据安全性
- 一个分区有多个副本,存储在不同Broker上
- 副本个数小于等于Broker个数
角色
- Leader副本
- 提高读写
- Follower副本
- 与Leader同步数据
- 如果Leader故障,选举新的Leader
Kafka存储机制
存储结构
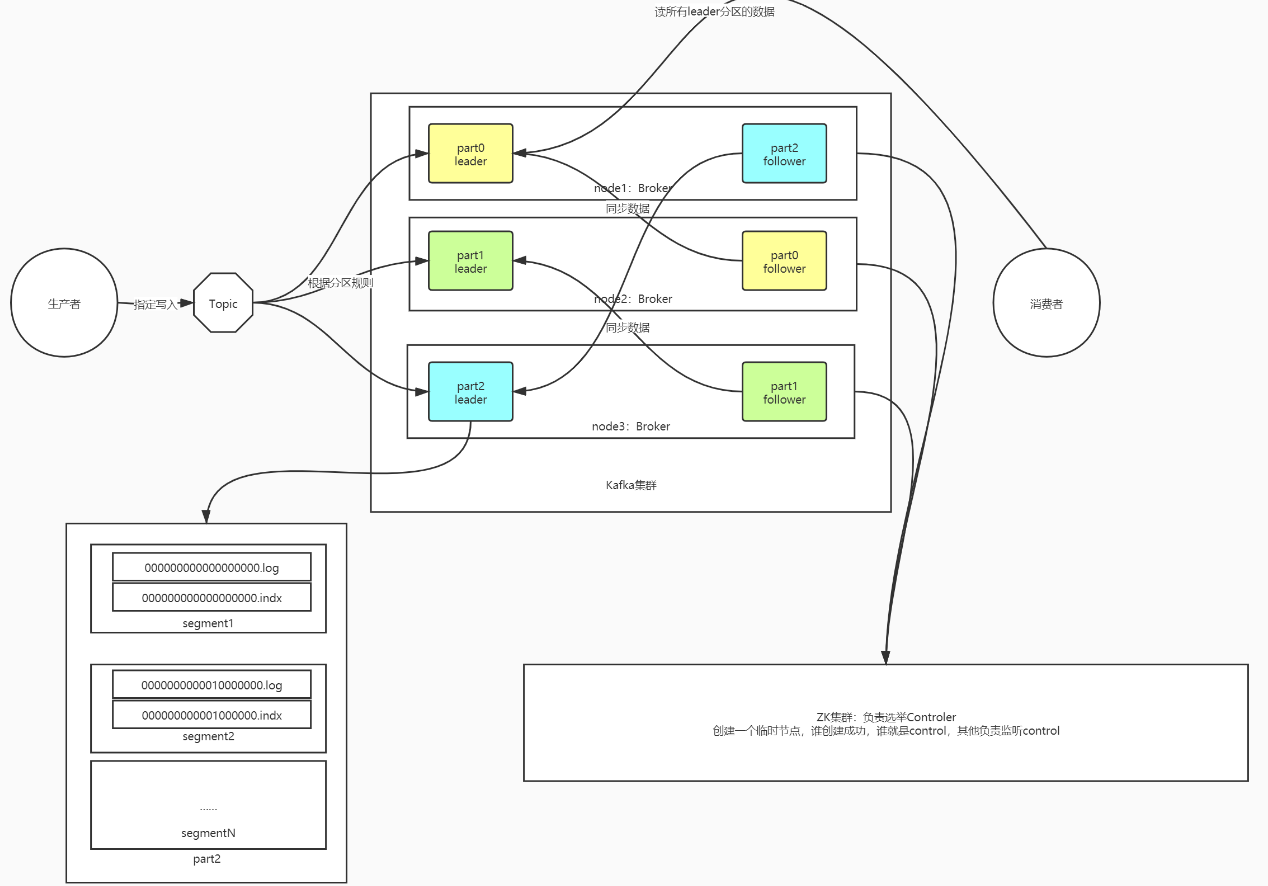
Broker存储节点
Producer生产者
Topic数据主题
- 用于区分不同的数据
Partition数据分区
- 分布式存储单元
- 名称构成:Topic名称+分区编号
Segment
- 分区段, 每个分区的数据存储在1个或多个Segment
- 每个Segment由一对文件构成
- .log存储的数据
- .index基于offset检索的稀疏索引
- .timeindex基于数据时间检索的索引
写入过程
- 生产者生产每一条数据,放入batch批次中, 达到时间或大小条件提交写入请求
- 根据分区规则,计算要写入的数据, 连接Kafka获取ZK地址, 用于获取元数据, 获取当前分区的Leader副本所有的Broker地址
- 请求对应的Broker写入数据, 先写入PageCache内存
- 后台实现同步或者异步写入顺序写磁盘,写入当前最新的Segment文件
Segment设计
设计思想
- 加快查询效率
- 减少删除数据的磁盘IO
基本实现
- .log存储真正的数据
- .index存储对应的.log的索引
划分规则
- 按照时间周期生成
- 按照文件大小生成
命名规则
- 以当前文件存储的最小offset来命名的
读取过程
- 消费者根据TopicPartitionOffset提交Kafka请求读取数据
- Kafka根据元数据信息, 找到分区对应的Leader副本所有的Broker
- 请求Leader副本所在Broker, 先读取PageCache, 通过零拷贝机制读取
- 如果PageCache没有, 就读取Segment文件端,先根据Offset找到对应的的Segment
- 将.log文件对应的.index文件加载到内存中, 根据index中的索引信息找到Offset在.log文件中最近位置
- 读取.log文件, 根据索引读取对应的Offset的数据
index索引设计
索引分类
- 全量索引:每一条数据都有索引
- 稀疏索引:只有部分数据有索引, Kafka使用
生成规则
- log.index.interval.bytes=4096
索引内容
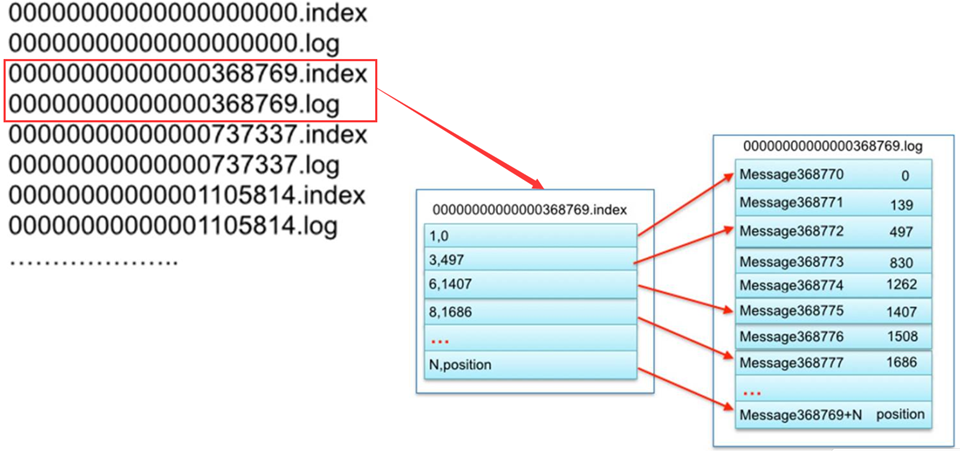
- 第1列:这条数据在这个文件中的位置
- 第2列:这条数据在文件中的物理偏移量
检索数据流程
- 先根据offset计算这条offset是这个文件中的第几条
- 读取.index索引,根据二分检索,从索引中找到离这条数据最近偏小的位置
- 读取.log文件从最近位置读取到要查找的数据
Kafka写入很快原因
- 先写PageCache操作系统级内存
- 顺序写入磁盘
Kafka读取很快原因
- 先读PageCache内存
- 通过索引读取磁盘
- 零拷贝机制,减少IO
- MMAP设计
生产分区
分区规则
指定分区
- 写入指定分区
指定key
- 按照key的Hash取余
- Hash分区: 只要Hash值一样就会进入相同分区
没有指定key
- 轮询分区: 每一条数据轮流放入不同分区(相同的数据会进入不同分区)
- 粘性分区StickyPartitioner: 全部数据随机选中一个分区
自定义开发生产分区器
- 开发一个类实现Partitioner接口
- 实现partition方法
- 生产者加载分区器
消费负载均衡
基本规则
- 一个分区只能被一个消费者消费
- 一个消费者可以消费多个分区数据
属性配置
partition.assignment.strategy = org.apache.kafka.clients.consumer.RangeAssignor
分配策略
RangeAssignor范围分配
- 说明
- 默认分配策略
- 每个消费者消费一定范围分区,尽量均分
- 如果不能均分,优先将分区分配给编号小的消费者
- 针对消费者的每个Topic进行范围分配
- 优点
- Topic较少会分配相对均衡
- 缺点
- Topic个数较多, 而且不能均分,负载失衡
- 应用
- 适用于Topic个数少,或者Topic能均分场景
RoundRobinAssignor轮询分配
- 说明
- 2.0版本前常用
- 按照Topic的名称和分区编号,轮询分配每个消费者
- 优点
- 多个消费者订阅一样Topic的场景, 能实现负载均衡
- 缺点
- 消费者订阅不同的Topic,会导致整体负载不均衡
- 应用
- 所有消费者订阅相同的Topic, 订阅关系都一样的场景
StickyAssignor粘性分配
- 说明
- 2.0版本后常用
- 相对的保证的分配的均衡
- 如果消费者故障, 尽量避免网络传输
- 尽量保证原理消费的分区不变,多余分区再均衡
- 优点
- 分配更均衡
- 消费者故障也可以避免负载失衡
- 应用
- 2.0版本之后建议使用
消费者消费过程
核心
- 根据Offset进行消费,每次从上一次的位置继续消费
- Topic + Partition + Offset
第1次消费
- 由属性决定auto.offset.reset = latest | earliest | none
- latest从最新位置开始
- earliest从最早位置开始,从offset 0 开始
- none 抛出异常
第2次开始
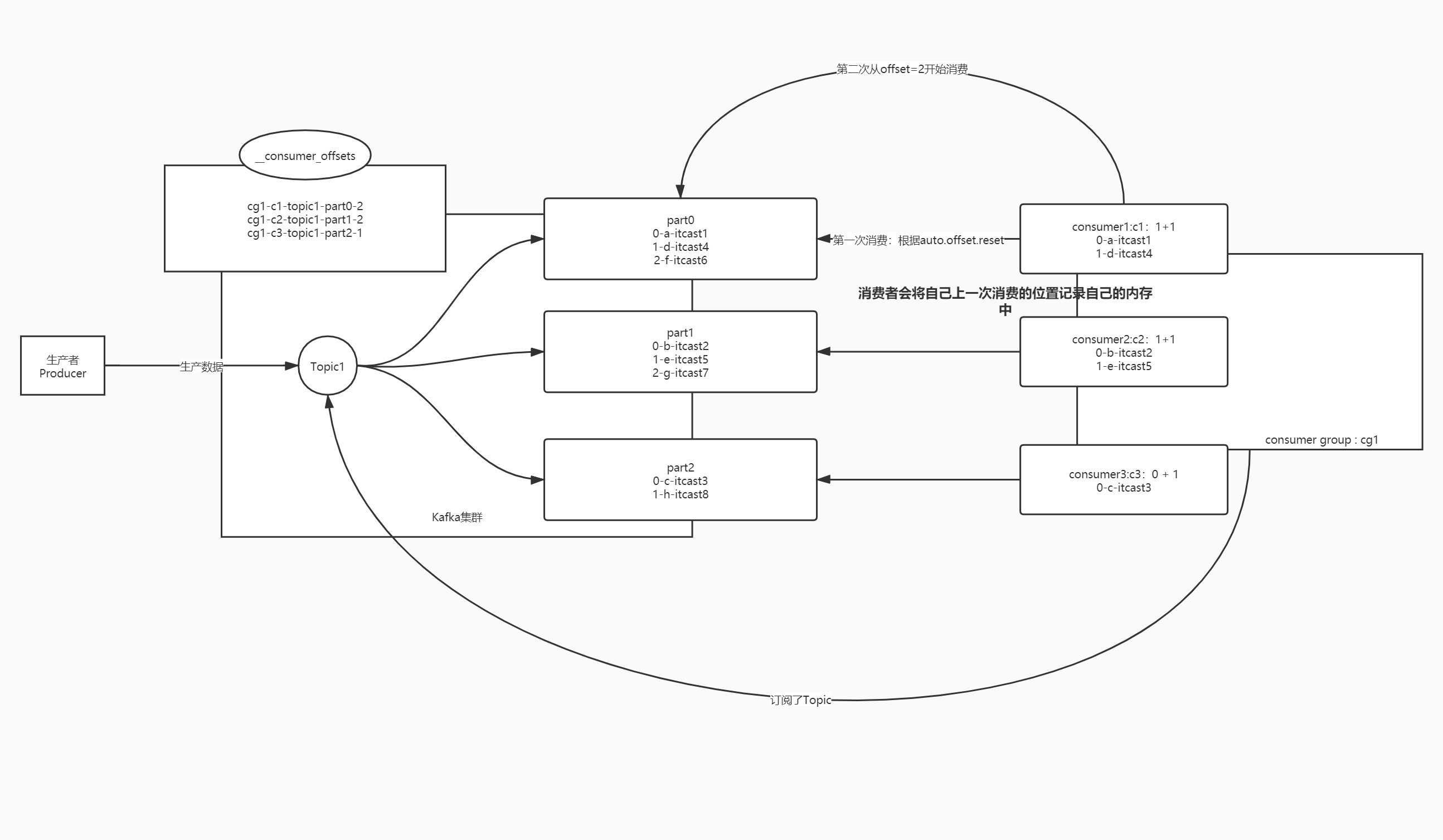
- 根据上一次消费的Offset位置+1继续进行消费
- 消费者将consumer offset记录在内存
- 下次消费consumer offset+1得到commit offset
Offset偏移量管理
说明
- Kafka将每个消费者消费的位置主动记录在一个Topic中__consumer_offsets
- 如果下次消费者没有给定请求offset,kafka就根据自己记录的offset来提供消费的位置
提交规则
- 根据时间自动提交
- props.setProperty(“enable.auto.commit”, “true”);
- props.setProperty(“auto.commit.interval.ms”, “1000”)
自动提交
- 消费丢失: 还没有消费就提交offset
- 消费重复: 消费了offset还没有提交
手动提交Topic Offset
关闭自动提交
- props.setProperty(“enable.auto.commit”, “false”);
消费完成后手动提交
- consumer.commitSync();
存在问题
- offset是分区级别,提交时topic级别,只要有一个分区失败,整个提交失败
- 通过手动提交分区offset实现
手动提交分区 Offset
消费每个分区数据
处理每个分区的数据
手动提交每个分区的offset
- consumer.commitSync(offsets);
自行管理offset
保存在外部系统
- MySQL Redis checkpoint zookeeper
保存offset
- JDBCreplace
读取offset
- JDBC
指定消费
- 指定Topic消费
- consumer.subscribe(Arrays.asList(“bigdata01”));
- 指定分区消费
- consumer.assign(Arrays.asList(part1,part2));
- 指定offset消费
- consumer.seek(TopicPartition,offset);
ACK机制和重试机制
概念
反向应答确认机制
作用
配合重试机制, 保证生产数据不丢失
参数说明
参数0
- 生产者写入一条数据到Kafka,不管Kafka有没有收到这条数据,都直接发送下一条
- 速度快但数据容易丢失
参数1
- 生产者写入一条数据到Kafka,等待Kafka将这条数据写入对应分区的Leader副本
- Kafka返回一个ack,生产者收到ack,发送下一条
- 性能和安全性折中,依旧存在数据丢失的风险
参数all或-1
- 生产者写入一条数据到Kafka,等待Kafka将这条数据写入对应分区Leader副本,
- 等待ISR副本同步成功以后,Kafka返回一个ack,生产者收到ack,发送下一条
- 安全但性能较差
特别说明
- 如果配置ack为1或者all/-1,生产者必须等待收到ack,再发送下一条
- 如果没有收到,超过一定时间,生产者重新发送重试机制
数据清理
概念
- Kafka用于实现实时消息队列的数据缓存
- 不需要永久性的存储数据
开启配置
- 开启清理
- log.cleaner.enable = true
- 清理规则
- log.cleanup.policy=delete | compact
delete清理规则
- 基于存活时间–常用
- 基于文件大小
- 基于offset消费规则
compact清理规则
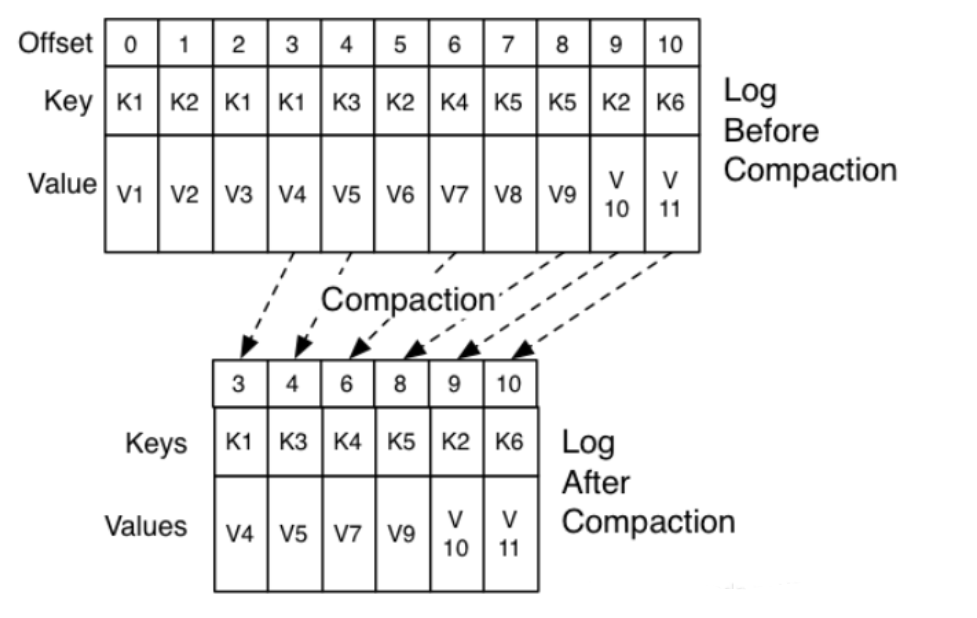
- 将重复的更新数据的老版本删除,保留新版本
- 要求每条数据必须要有Key,根据Key来判断是否重复
集群架构
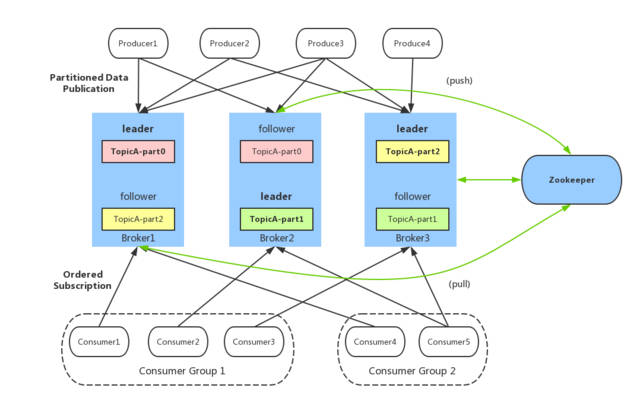
角色
Kafka分布式主从架构
- Kafka Controller主节点
- 特殊Broker, 启动时ZK选举得出, 负责普通Broker工作
- 管理所有从节点,Topic,分区,副本
- 决定分区的Leader和Follower
- Kafka Broker从节点
- 对外提供读写
- 监听Controller,如果故障重写选举
Zookeeper
- 存储Kafka元数据
- 辅助选举Kafka的主节点, 抢注模式
搭建部署
- 解压安装
- 修改配置文件
- 分发文件
- 添加环境变量
- 启动和停止脚本
Topic管理
bin/kafka-topics.sh --create --topic bigdata01 --partitions 3 --replication-factor 2 --bootstrap-server node1:9092,node2:9092,node3:9092
■ --create创建
■ --topic指定名称
■ --partitions分区个数
■ --replication-factor分区的副本个数
■ --bootstrap-server指定Kafka服务端地址
○ 列举--list
○ 查看--describe
○ 删除--deleteKafka API 应用
大数据应用
命令行
- 一般只用于topic的管理:创建、删除
生产者
- 数据采集工具
消费者
- 实时采集工具
生产者API
KafkaProducer生产者连接对象
send生产者用于发送数据到Kafka中的方法
- send(ProducerRecord)
- ProducerRecord(Topic、Key、Value)
- ProducerRecord(Topic、Value)
- ProducerRecord(Topic、Partition、Key、Value)
ProducerRecord发送的数据, 3中类型
消费者API
KafkaConsumer消费者连接对象
- subscribe()订阅Topic
- poll()消费Topic
ConsumerRecords返回多条数据集合
ConsumerRecord每一条数据
- .topic
- .partition
- .offset
- .key
- .value
一次性语义
分类
at-most-once至多1次
- 数据丢失
at-least-once至少1次
- 数据重复
exactly-once有且只有1次
- 只消费处理成功1次
- 消息队列目标
Kafka如何实现一次性语言
生产不丢失
- ACK机制+retries重试机制
生产不重复
- 问题根源: ACK丢失
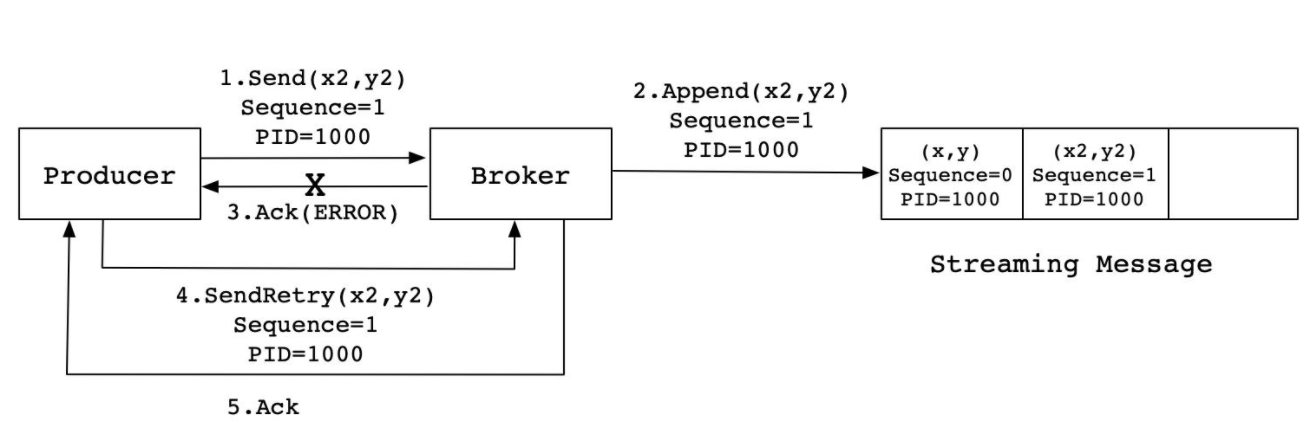
- 幂等性机制f(x) = f(f(x))
- 在每条数据中增加一个数据id,下一条数据会比上一条数据id多1
- Kafka会根据id进行判断是否写入过了
消费不丢失不重复
- 所有消费者按照offset顺序消费即可
- 保证任何场景下消费者都能知道上一次的Offset
- 实现
- Kafka将消费者的offset存储在__consumer-offsets
- offset存储在一种可靠外部存储中,手动管理offset
面试知识
分区副本名词
- AR所有副本
- ISR可用副本
- OSR不可用副本
数据同步名词
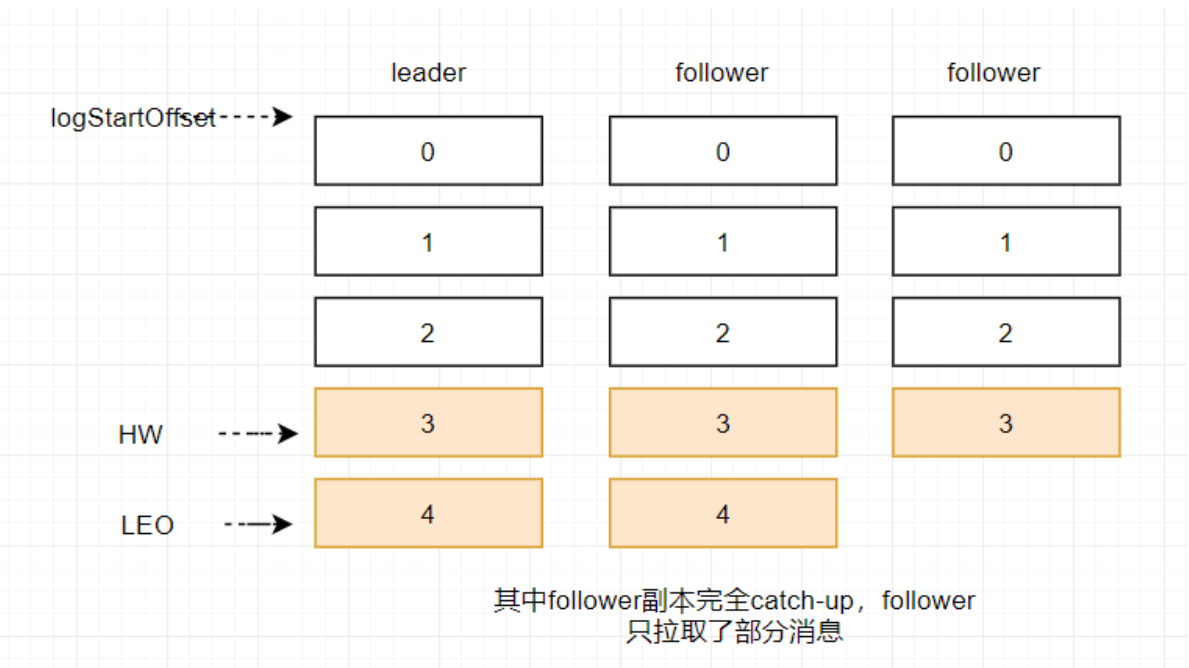
- HW当前这个分区所有副本同步的最低位置 + 1,消费者能消费到的最大位置
- LEO当前每个副本已经写入数据的最新位置 + 1
Leader选举
Controller选举
- Kafka主从节点选举
- ZK辅助实现
Leader选举
- 分区副本的角色选举
- Controller根据负载均衡选举
数据限流
问题
- 生产太快,消费跟不上
- 生产太慢, 消费速度太快
限制生产
限制消费
Vol.12 Kafka 核心工作原理小记
https://jface001.github.io/2023/02/26/vol12-Kafka核心工作原理小记/