Vol.13 浅谈数据仓库DataWarehouse
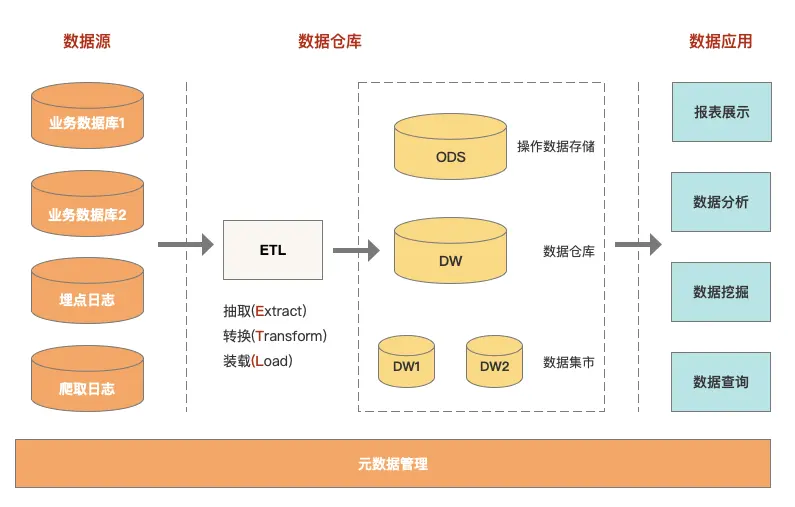
数据仓库是什么
数据仓库是什么?根据 Google Cloud 的介绍:
数据仓库是一种企业系统,用于分析和报告来自多个来源的结构化和半结构化数据,例如销售终端交易、营销自动化、客户关系管理等。数据仓库适用于点对点分析以及自定义报告。数据仓库可以将当前数据和历史数据都存储在一个地方,旨在提供长期数据视图,这使其成为商业智能的主要组成部分。
从这个介绍来看,我们可以将数据仓库理解为一个业务数据跟日志数据的仓库,跟业务数据库的区别在于它主要用于数据分析跟数据挖掘,从数据当中挖掘价值,提供企业用于战略分析、战略决策、业务拓展等。数据仓库已经是不一个新鲜的技术架构,如今的中小型企业都讲究数据驱动,只要业务跑起来了,就开始建立数据仓库,利用大数据进行营销投放,精准营销。
就从我的粗浅的工作经验来说,很多公司虽然建立了数据仓库,但大部分并不成熟,存在很多问题,比如成本偏高、脏数据过多、维护困难、架构复杂等等,感觉大家仅仅把数据仓库当成一个普通的业务数据库。我想来说说我的对一个成熟的数据仓库的理解。
一个成熟的数据仓库应该具备哪些特点
数据是简单干净的,易于管理的
业务数据跟日志数据经过抽取、转换、同步到数据仓库,因而除了 ODS 层之外,在数据仓库其它分层中的数据应该是干净简单的,易于使用的。我工作当中经常发现因为脏数据造成调度任务失败,报表数据异常,原因可能是业务库数据逻辑变更了、业务系统故障等等,但我感觉这些问题都应该在 ELT 环节发现并处理。一个成熟的数据仓库,应该有规范的数据处理流程,对于不同的数据类型处理方式、脏数据的监控跟过滤、数仓分层的规范跟标准、字典表的维护管理等等,这些应该在数据仓库建立之处就定下,所有相关的开发者跟使用者,都应该遵守并执行。
分层是合理的,健全的
数据仓库的理念之一就是数仓分层,将数据分层不同的层次,通常来说会分为:贴源层、明细层、集市层跟报表标签层,合理的分层能大大减少计算成本跟维护成本,提高使用效率。健全的数仓分层应该是清晰明确的,没有跨层引用、数据表字段清晰明确、统一的指标体系、健全的字典表体系、合理的临时表关系方式等等。这些当中我感触最深的就是跨层引用跟字典表维护,我接手过太多脚本里面充满着 case when 分支逻辑、无人维护的临时表,往往要花大量的时间摸排底层数据,吃力不讨好,不敢轻易改动。
简单的架构、合理的调度管理跟任务管理
数据仓库大部分都是基于 Hadoop + hive 架构,计算引擎会引入 spark 、 presto 、flink 等,当然也有使用新型的数据库:clickhouse 、Doris 等。无论使用那一种,架构都应该的简单的明确的,不同的处理引擎跟数据库应该拥有准确的定位,数据的流转链路应该是清晰的,易于维护的。调度逻辑更为重要,数据从哪里入库、如何入库、上下游的关系、故障的监控定位处理、月初月末高峰时期任务的监控处理等等,这些都应该关注到。任务调度是数据仓库最容易出问题的一个环境,基本每个月这都会遇到任务调度异常、上游任务失败影响到业务投放。调度周期不合理跟缺乏完善的监控体系跟任务处理规范是根源。就像 Google 提出大数据计算之初说到的:硬件故障是常态,分布式计算应该在产生故障的时候也能正常运行,这句话也适用数据仓库。
数据仓库工程师未来应该掌握的技能有哪些
上面都是个人的粗浅看法,有些问题工作之初就听前辈提起,工作之后感触更深了。大数据跟数据仓库在国内已经发展了十几年,最近 chatGPT 大火,大数据技术将会再一次成为 “基建”,因为再好的 AI 模型也需要合理的特征语料来训练,一个合理的数据仓库可以大大提高模型训练的效率跟效果。
那么,未来数据仓库工程师应该掌握哪些新的技能呢? 我感觉是元原生跟容器技术,go 语言跟 docker 、k8s 是未来必须掌握的技能。AI 模型需要的算力更大,传统的机房服务器可能很难满足常规需求,企业会更多的使用云技术来训练管理。云技术在国内也发展了十多年,如今我也感觉将再一次成为浪潮。